1. MNIST란?
MINIST는 손글씨 숫자 이미지들이 모여있는 데이터로, 컴퓨터 비전 데이터라고도 한다.
다음과 같은 손글씨 이미지로 구성되어있다.

이 데이터는 눈으로 봤을 때는 그냥 손글씨 숫자이지만, 각 이미지의 숫자가 무엇인지에 대한 라벨이 붙어있다. 인공신경망에서 라벨은 중요한 역할을 한다. 인공신경망 함수를 통해 출력된 값과 비교하여 상관관계를 따져보는 과정이 학습에서 중요한 부분이기 때문이다!
MINIST 이미지는 28*28 크기의 이미지다. 또한 흑백이미지이므로, 채널은 하나다.
(rgb 이미지는 r, g, b 세개의 채널)
2. MNIST 사용을 위한 Module
본격적으로 코딩을 하기 전에 먼저 module을 import하자.
대략 넘파이(numpy), matplotlib, 토치(torch) 라이브러리를 사용한다.
numpy: 수학적 계산
matplotlib: 그래프 그리기(데이터 시각화)
torch: 데이터 조작
import numpy as np
import matplotlib.pyplot as plt
import torch
from torchvision import datasets
import torchvision.transforms as transforms
(참고)
주피터 노트북 내에서 딥러닝 모델을 설계할 때 사용하는 장비의 버전을 확인할 수 있다. 주피터 노트북이 실행 중이라서 아나콘다 프롬프트를 사용할 수 없을 때, 다음과 같은 코드로 장비를 확인해보자.
if torch.cuda.is_available():
device = torch.device('cuda')
else:
device = torch.device('cpu')
print('Using PyTorch version:', torch.__version__, ' Device:', device)<실행결과>

위 코드의 cuda는 GPU이다. 러닝할 준비를 하는데 웬 GPU?라고 생각하여 좀 더 찾아보았다.
GPU란 Graphic Processing Unit(그래픽 처리장치)로 프로세서다. 그래픽 처리 장치 답게 3D 모델링에 특화되어 있다. (참고 자료 : https://tech.ktcloud.com/17) Neural network train을 할 때 성능을 비교하기 위해 loss funtion, optimizer 등 여러 가지 model을 돌리는데, 이때 GPU를 사용한다.
torch.cuda.is_available(): cuda가 사용 가능하면 true 반환.
3. MNIST 데이터 다운로드 하기
일단 MINIST 데이터셋을 활용하기 위해서는 MINIST 데이터를 불러와야 한다.
이때 Train data와 Test data를 분리하는데, Train data는 내가 학습 시킬 부분, Test data는 말 그대로 확인용이다.
BATCH_SIZE = 32
train_data = datasets.MNIST('./data', train=True, download=True, transform=transforms.ToTensor())
test_data = datasets.MNIST('./data', train=False, download=True, transform=transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=False)
test_loader = torch.utils.data.DataLoader(dataset=test_data, batch_size=BATCH_SIZE, shuffle=False)train_data와 train_loader는 데이터 셋 객체이다
- train : 데스트용 데이터 = True, 학습용 데이터 = False
- transform : 데이터의 형태. 일반 이미지는 (H, W, C)의 형태와 0 ~ 255 사이의 값을 갖는다.
pytorch는 (C, H, W) 형태와 0 ~ 1 사이의 값을 가진다.
transform.ToTensor() : 일반이미지를 파이토치의 텐서(pytorch tensor)로 변환.
- suffle : 무작위 순서
# 훈련을 위한 데이터 로딩딩
# x : 입력 데이터
# y : 출력 데이터
#
# Model / data parameters
num_classes = 10
input_shape = (28, 28, 1)
# Load the data and split it between train and test sets
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()4. 첫번째 batch 데이터의 크기와 타입을 확인하기
.size()와 .type()을 통해 데이터의 크기와 타입을 확인한다.
for (X_train, y_train) in train_loader:
print('X_train:', X_train.size(), 'type:', X_train.type())
print('y_train:', y_train.size(), 'type:', y_train.type())
break<실행결과>
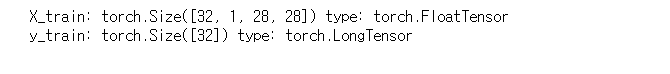
from tensorflow.python.framework.indexed_slices import internal_convert_n_to_tensor_or_indexed_slices
# 데이터 몇 개 확인하기
#
import matplotlib.pyplot as plt
index = 0
print("x_train.shape == ", x_train.shape)
print("y_train.shape == ", y_train.shape)5. 첫번째 batch 데이터를 시각화하여 확인하기
pltsize=1
plt.figure(figsize=(10*pltsize, pltsize))
for i in range(10):
plt.subplot(1,10,i+1)
plt.axis('off')
plt.title('Class: '+str(y_train[i].item()))
image=X_train[i]
plt.imshow(image.reshape(28,28),cmap='gist_yarg')plt.subplot: 여러개의 그래프 한꺼번에 그리는 메소드. 각 숫자 이미지에 해당하는 그래프.
(1행 10열의 그림을 i+1번 그린다. i = 0~9)
plt.axis(): X,Y 축 범위를 지정하거나 반환한다.
torch.imem()을 하면 저장된 값만 가져온다.
plt.imshow(): 원하는 사이즈의 픽셀(행렬)을 원하는 색으로 칸을 채워서 만든 그림을 그려준다.
cmap = color map으로 색깔을 지정해주는 조건이다.
<실행결과>

# 입력 데이터/출력 데이터 확인
#
index = 0
plt.imshow(x_train[index])
plt.show()
print("y_train[index] == ", y_train[index])+) 6. 데이터 전처리
# 훈련 모델에 입력하기 위한 데이터 변환 (전처리리)
#
# Scale images to the [0, 1] range
# 픽셀 값을 0과 1사이의 값으로 만드는 것 /255
x_train = x_train.astype("float32") / 255 # 색상 수 : 255
x_test = x_test.astype("float32") / 255
# Make sure images have shape (28, 28, 1)
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
print("x_train shape:", x_train.shape)
print(x_train.shape[0], "train samples")
print(x_test.shape[0], "test samples")
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)+) 7. 모델 생성
# 머신러닝 모델 생성
#
model = keras.Sequential(
[
keras.Input(shape=input_shape),
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(num_classes, activation="softmax"),
]
)
model.summary()+) 8. 모델 훈련
# 머신러닝 모델 훈련
#
batch_size = 128
epochs = 15
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1)+)9. 모델 평가/ 예측
# 훈련된 모델 평가
#
score = model.evaluate(x_test, y_test, verbose=0)
print("Test loss:", score[0])
print("Test accuracy:", score[1])
# 모델 예측
#
y_pred = model.predict(x_test)+)10. 예측 결과 확인
# 예측 결과 확인
#
index = 1
plt.imshow(x_test[index])
plt.show()
print("y_pred[ ", index, " ] == ", y_pred[index], " : ", np.argmax(y_pred[index]))
print("y_test[ ", index, " ] == ", y_test[index], " : ", np.argmax(y_test[index]))
(GPU 참고자료)
[Pytorch] 특정 GPU 사용하기 / 여러개의 multi GPU parallel 하게 사용하기
Neural network를 train을 하다보면 성능을 비교하기 위해 loss function, optimizer 등이 상이한 여러 가지 model을 돌려볼 일이 수도 없이 많다. 이 때, 한 장의 GPU만 있다면 어쩔 수 없지만 여러장의 GPU가 존
artiiicy.tistory.com
💕 피드백과 질문은 언제든 환영입니다. 💕
'ML' 카테고리의 다른 글
| [python/AI] Python 외부 라이브러리 설치 및 관리 총정리 (0) | 2023.07.15 |
|---|---|
| [python/AI] 텐서(tensor)란? 텐서(tensor) 개념 / 파이토치(pytorch)에서의 활용/ 인공지능(AI) 기본 개념 (0) | 2022.11.01 |
| [python/AI] matplotlib 개념/사용/데이터시각화 (2) | 2022.10.25 |