냉시피 프로젝트의 모든 API 개발과 배포가 완료되었다.
이후 개발 마무리 회의에서 내가 구현한 Recipe API의 성능 최적화 작업을 시작하기로 했다.
성능 최적화를 고민한 이유
성능 최적화 전 Recipe API 로직은 다음과 같다.
- GET 요청이 들어오면 Crawling 함수를 실행하여 "만개의 레시피" 사이트 크롤링
- database Recipe Entity의 recipe_name column을 확인하여 중복되지 않은 경우 크롤링 정보 db에 저장
- 사용자가 저장한 재료(Ingredient Entity)와 저장된 Recipe 목록(Recipe Entity)을 비교하여, 사용자가 저장한 재료를 기반으로 레시피 목록을 출력
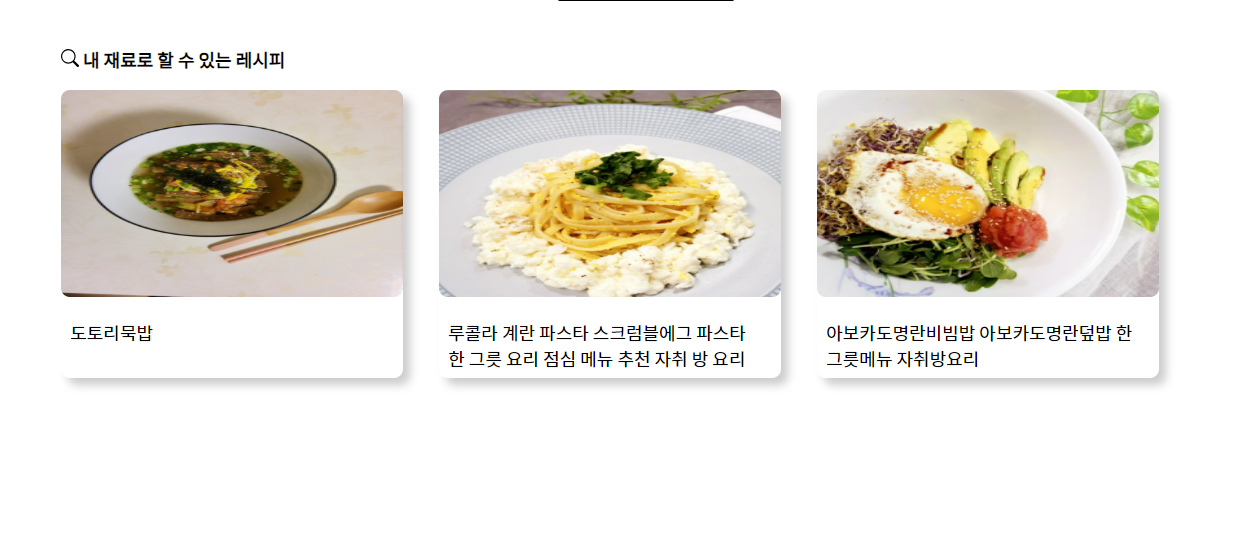
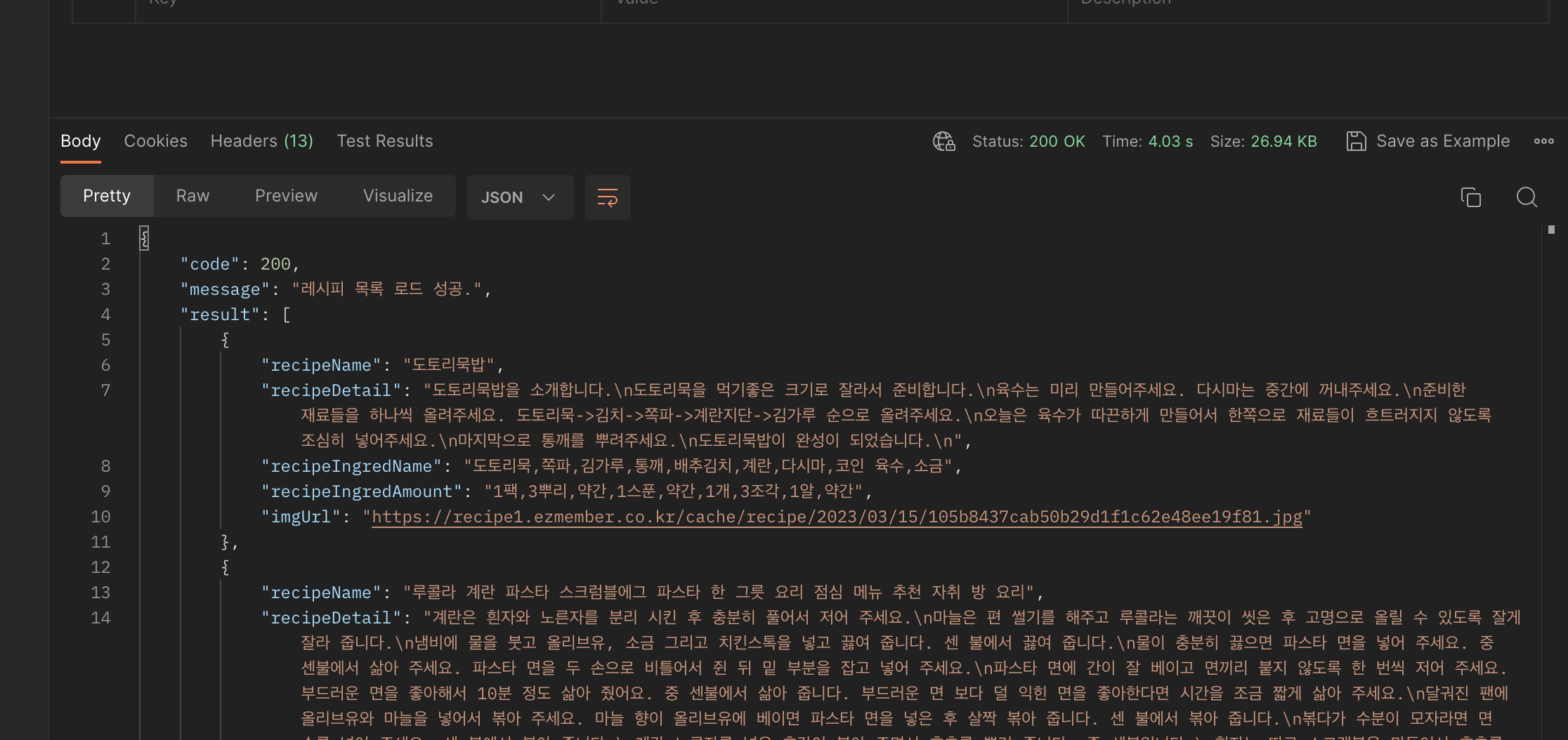
위와 같이 postman, nengcipe 서버 모두에서 api가 잘 작동하는 걸 확인할 수 있었다.
하지만 이렇게 api를 구현한다면 사용자의 요청이 들어올 때 마다 크롤링 > db 작업을 진행해야 하므로 필요없는 작업을 반복적으로 수행하게 된다. 크롤링 > db 저장은 한번만 잘 해놓고, 주기적으로 Update만 해주면 서비스 운영에 문제없기 때문이다.
성능 최적화를 위한 api 로직
- python으로 크롤링
- pymysql로 recipe_name 중복 체크(같은 레시피가 중복되어 저장되는 것을 방지하기 위해)
- pymysql로 database에 크롤링 값 저장
- 크롤링을 위해 사용한 패키지와 pymysql, 크롤링 로직이 담긴 모든 코드를 압축하여 AWS Lambda에 업로드
- Lambda에서 크롤링 데이터 업데이트 주기를 설정하고 database에 설정한 주기 별로 저장
개발 과정
- 우선 내가 작성한 Java Crawling 코드를 Python Crawling 코드로 변환한다.
- 같은 파일 내에 pymysql을 구현하는 코드를 작성한다.
- lambda에 python 크롤링 코드를 올리고 packge zip 파일 올리기
python package 로컬사용 & zip 파일로 만들기
로컬(원하는 로컬 디렉토리)에 python packge를 설치하는 명령어는 다음과 같다.
처음에 그냥 pip install packageName 명령어로 다운 했는데 원하는 디렉토리에서 이 명령어를 실행해도, 계속 "/.local/lib/python3.10/site-packages" 이 경로에 설치가 되는거다!_!_!
내 예상으로는 anaconda가 설치된 곳에 자동으로 설치되는 듯하다. 그래서 아래 명령어 옵션을 추가해주어야 한다.
pip install packageName -t .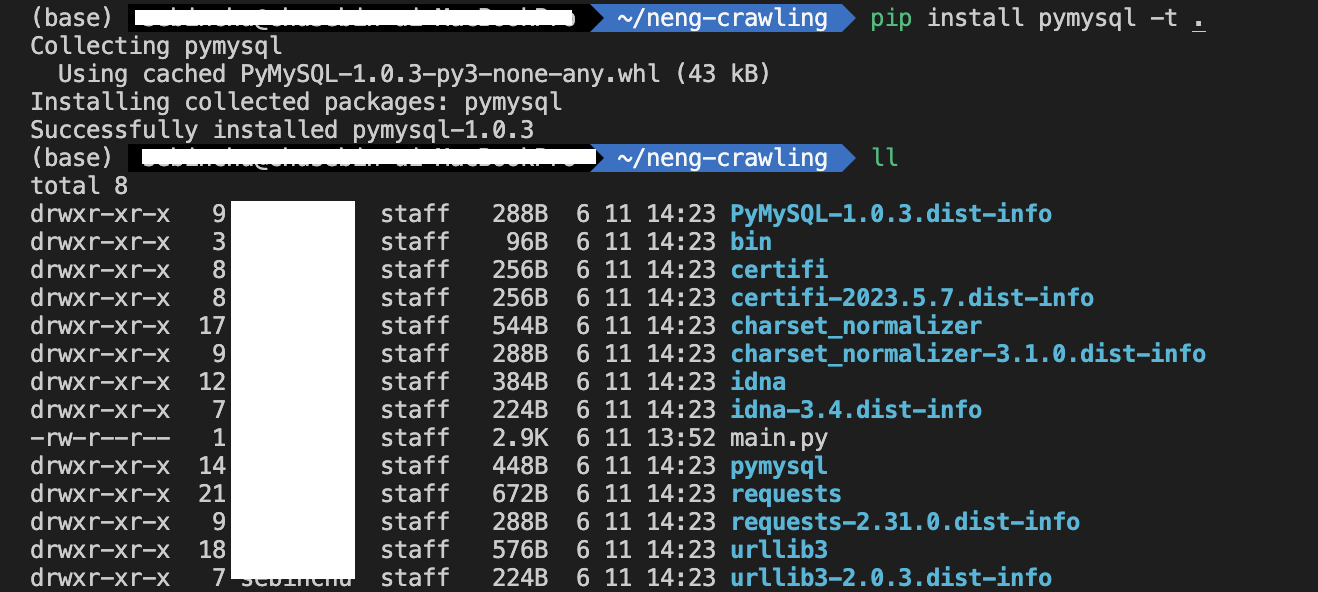
python에서 mysql 사용하기
- MySQL 연결하기
- mydb = pymysql.connect()
- 커서 생성하기
- cursor=pymysql.cursor()
- 테이블 만들기
- cursor.execute("CREATE TABLE aa")
- 데이터 입력하기
- cursor.execute("INSERT aa")
- 입력한 데이터 저장하기
- mydb.commit()
- Mysql, cursor 연결 종료하기
- mydb.close()
- cursor.close()
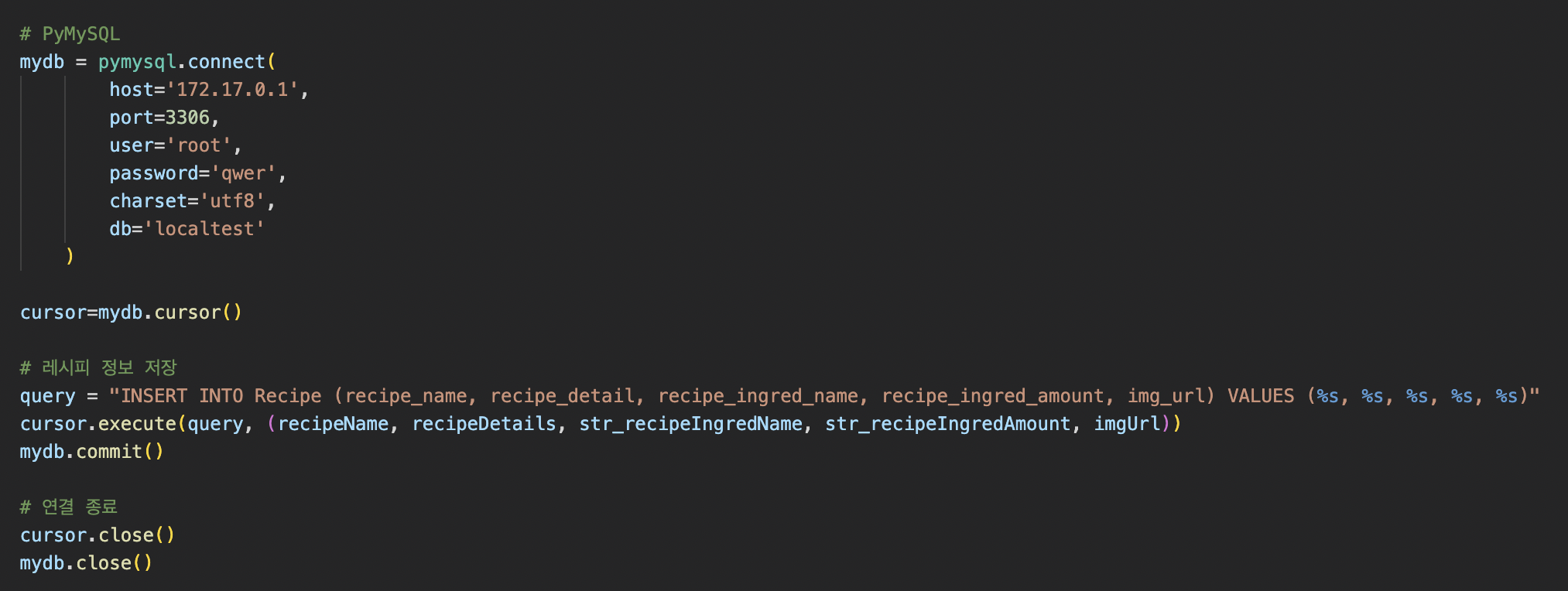
crawling -> pymysql -> database 결과
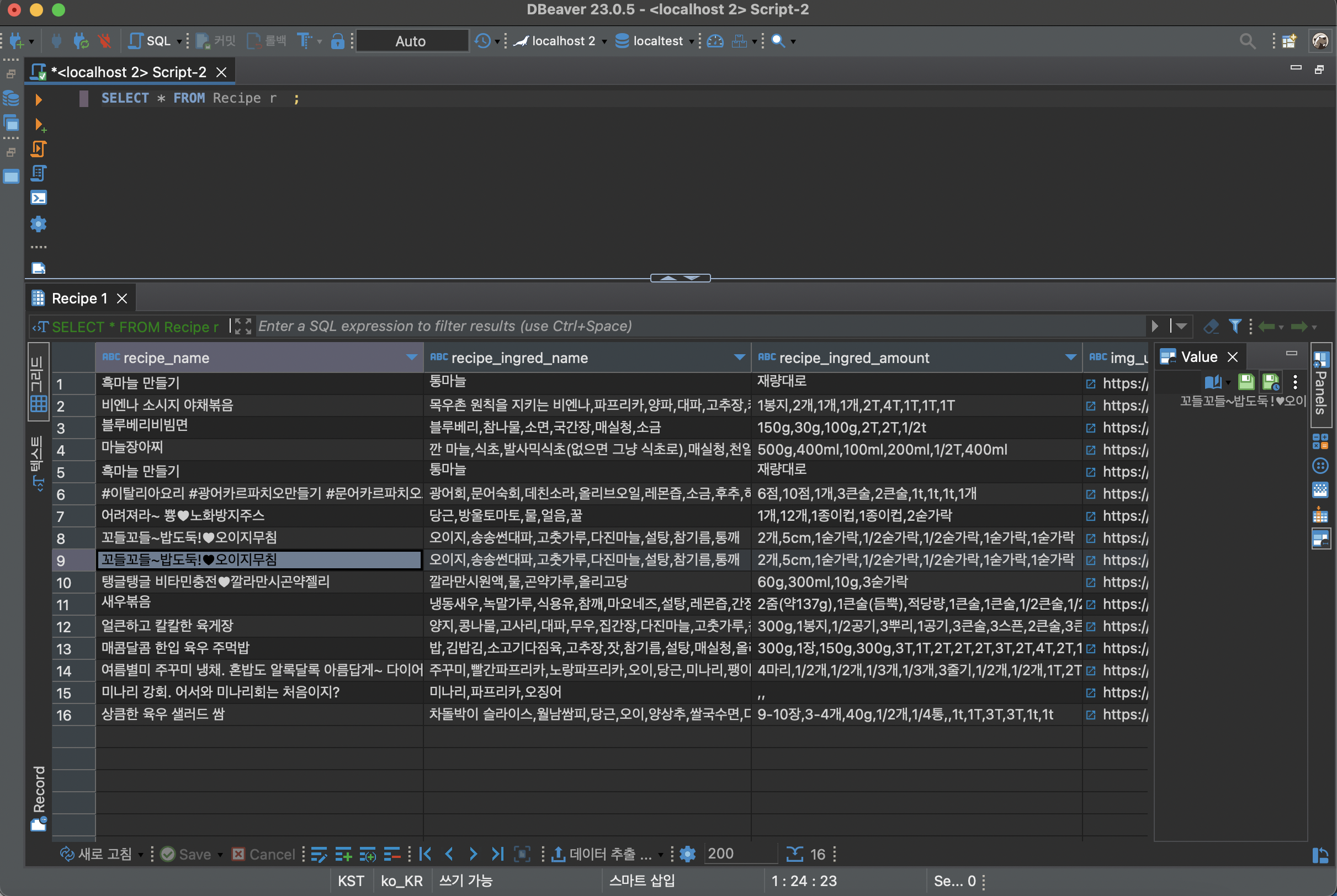
Database 상태를 보면 같은 Recipe가 2번 이상 중복되어 저장된다. 이를 방지하기 위해 쿼리문을 다시 추가하였다.
Pymysql 코드를 모두 작성하고 test를 했을 때 계속 DB에 값이 저장이 안 되는거다..
그런데 Ingredient 더미데이터는 또 저장이 잘 되어서 쿼리문의 문제인가 싶었는데, recipe 정보가 담기는 컬럼의 제약조건 때문이었다. (ERD를 잘 보자..!!)
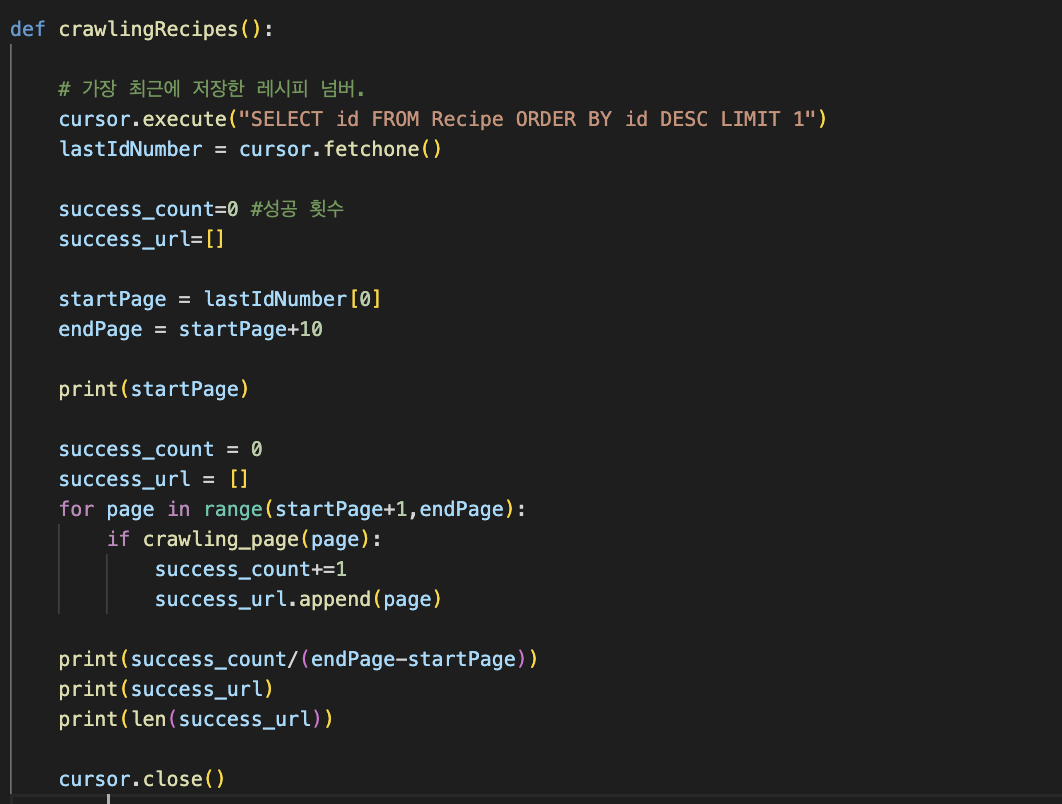
이제 로컬 DB에서 중복값을 제거하는 코드를 구현해보자.
query = "INSERT INTO Recipe (recipe_name, recipe_detail, recipe_ingred_name, recipe_ingred_amount, img_url) SELECT %s, %s, %s, %s, %s FROM Recipe WHERE NOT EXISTS (SELECT recipe_name FROM Recipe WHERE recipe_name = %s) LIMIT 1"
cursor.execute(query, (recipeName, recipeDetails, str_recipeIngredName, str_recipeIngredAmount, imgUrl, recipeName))
mydb.commit()
또, Lambda에서 Recipe 값을 갱신해주어야 하므로 가장 최근에 저장한 RecipeNumber로 업데이트를 해주었다.
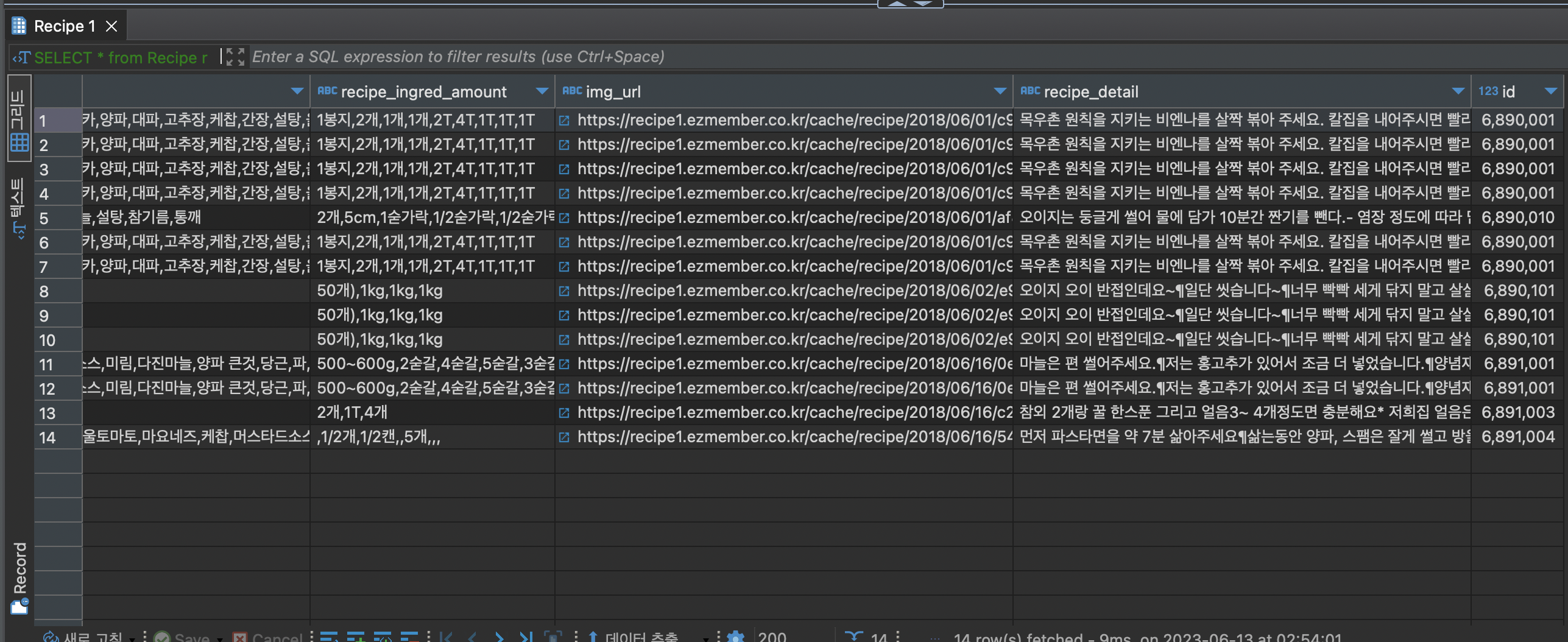
값이 중복되는 건 인덱스를 임의의 값으로 넣어 테스트를 했기 떄문이다.
이렇게 크롤링 값을 중복없이 저장하고, Lambda에서 주기적을 업데이트를 하기 위한 로직을 다 짰다.
2탄에서 Lambda에 올리는 과정을 작성할 예정이다.
'회고 & 후기 > 개발 일지' 카테고리의 다른 글
| [개발일지] 배포 삽질기 | 심볼릭 링크, 리눅스의 Capacities, ufw, netstat (0) | 2024.03.25 |
|---|---|
| [개발일지] 개발자가 가져야하는 습관, git pull (0) | 2023.09.20 |
| [개발일지] git 영역(Staging)과 소스관리 | 브랜치 전략, PR과 Merge | 협업 시 git 잘 쓰는 방법 (1) | 2023.09.16 |
| [개발 일지] 도커 컨테이너에서 웹 개발하기 (1) (0) | 2023.05.15 |
냉시피 프로젝트의 모든 API 개발과 배포가 완료되었다.
이후 개발 마무리 회의에서 내가 구현한 Recipe API의 성능 최적화 작업을 시작하기로 했다.
성능 최적화를 고민한 이유
성능 최적화 전 Recipe API 로직은 다음과 같다.
- GET 요청이 들어오면 Crawling 함수를 실행하여 "만개의 레시피" 사이트 크롤링
- database Recipe Entity의 recipe_name column을 확인하여 중복되지 않은 경우 크롤링 정보 db에 저장
- 사용자가 저장한 재료(Ingredient Entity)와 저장된 Recipe 목록(Recipe Entity)을 비교하여, 사용자가 저장한 재료를 기반으로 레시피 목록을 출력
위와 같이 postman, nengcipe 서버 모두에서 api가 잘 작동하는 걸 확인할 수 있었다.
하지만 이렇게 api를 구현한다면 사용자의 요청이 들어올 때 마다 크롤링 > db 작업을 진행해야 하므로 필요없는 작업을 반복적으로 수행하게 된다. 크롤링 > db 저장은 한번만 잘 해놓고, 주기적으로 Update만 해주면 서비스 운영에 문제없기 때문이다.
성능 최적화를 위한 api 로직
- python으로 크롤링
- pymysql로 recipe_name 중복 체크(같은 레시피가 중복되어 저장되는 것을 방지하기 위해)
- pymysql로 database에 크롤링 값 저장
- 크롤링을 위해 사용한 패키지와 pymysql, 크롤링 로직이 담긴 모든 코드를 압축하여 AWS Lambda에 업로드
- Lambda에서 크롤링 데이터 업데이트 주기를 설정하고 database에 설정한 주기 별로 저장
개발 과정
- 우선 내가 작성한 Java Crawling 코드를 Python Crawling 코드로 변환한다.
- 같은 파일 내에 pymysql을 구현하는 코드를 작성한다.
- lambda에 python 크롤링 코드를 올리고 packge zip 파일 올리기
python package 로컬사용 & zip 파일로 만들기
로컬(원하는 로컬 디렉토리)에 python packge를 설치하는 명령어는 다음과 같다.
처음에 그냥 pip install packageName 명령어로 다운 했는데 원하는 디렉토리에서 이 명령어를 실행해도, 계속 "/.local/lib/python3.10/site-packages" 이 경로에 설치가 되는거다!_!_!
내 예상으로는 anaconda가 설치된 곳에 자동으로 설치되는 듯하다. 그래서 아래 명령어 옵션을 추가해주어야 한다.
pip install packageName -t .
python에서 mysql 사용하기
- MySQL 연결하기
- mydb = pymysql.connect()
- 커서 생성하기
- cursor=pymysql.cursor()
- 테이블 만들기
- cursor.execute("CREATE TABLE aa")
- 데이터 입력하기
- cursor.execute("INSERT aa")
- 입력한 데이터 저장하기
- mydb.commit()
- Mysql, cursor 연결 종료하기
- mydb.close()
- cursor.close()
crawling -> pymysql -> database 결과
Database 상태를 보면 같은 Recipe가 2번 이상 중복되어 저장된다. 이를 방지하기 위해 쿼리문을 다시 추가하였다.
Pymysql 코드를 모두 작성하고 test를 했을 때 계속 DB에 값이 저장이 안 되는거다..
그런데 Ingredient 더미데이터는 또 저장이 잘 되어서 쿼리문의 문제인가 싶었는데, recipe 정보가 담기는 컬럼의 제약조건 때문이었다. (ERD를 잘 보자..!!)
이제 로컬 DB에서 중복값을 제거하는 코드를 구현해보자.
query = "INSERT INTO Recipe (recipe_name, recipe_detail, recipe_ingred_name, recipe_ingred_amount, img_url) SELECT %s, %s, %s, %s, %s FROM Recipe WHERE NOT EXISTS (SELECT recipe_name FROM Recipe WHERE recipe_name = %s) LIMIT 1"
cursor.execute(query, (recipeName, recipeDetails, str_recipeIngredName, str_recipeIngredAmount, imgUrl, recipeName))
mydb.commit()
또, Lambda에서 Recipe 값을 갱신해주어야 하므로 가장 최근에 저장한 RecipeNumber로 업데이트를 해주었다.
값이 중복되는 건 인덱스를 임의의 값으로 넣어 테스트를 했기 떄문이다.
이렇게 크롤링 값을 중복없이 저장하고, Lambda에서 주기적을 업데이트를 하기 위한 로직을 다 짰다.
2탄에서 Lambda에 올리는 과정을 작성할 예정이다.
'회고 & 후기 > 개발 일지' 카테고리의 다른 글
| [개발일지] 배포 삽질기 | 심볼릭 링크, 리눅스의 Capacities, ufw, netstat (0) | 2024.03.25 |
|---|---|
| [개발일지] 개발자가 가져야하는 습관, git pull (0) | 2023.09.20 |
| [개발일지] git 영역(Staging)과 소스관리 | 브랜치 전략, PR과 Merge | 협업 시 git 잘 쓰는 방법 (1) | 2023.09.16 |
| [개발 일지] 도커 컨테이너에서 웹 개발하기 (1) (0) | 2023.05.15 |