개요
2025년 첫 커리어를 시작하고 SRE로서 회사에 기여한 일들을 정리해본다.
(그대로 옮기니까 가독성이 좀 떨어지긴 한데..ㅋㅋ 작업 관련 스레드 링크를 모두 붙였다가 이걸 이미지와 글로 풀어내려니까 어려운 점..)
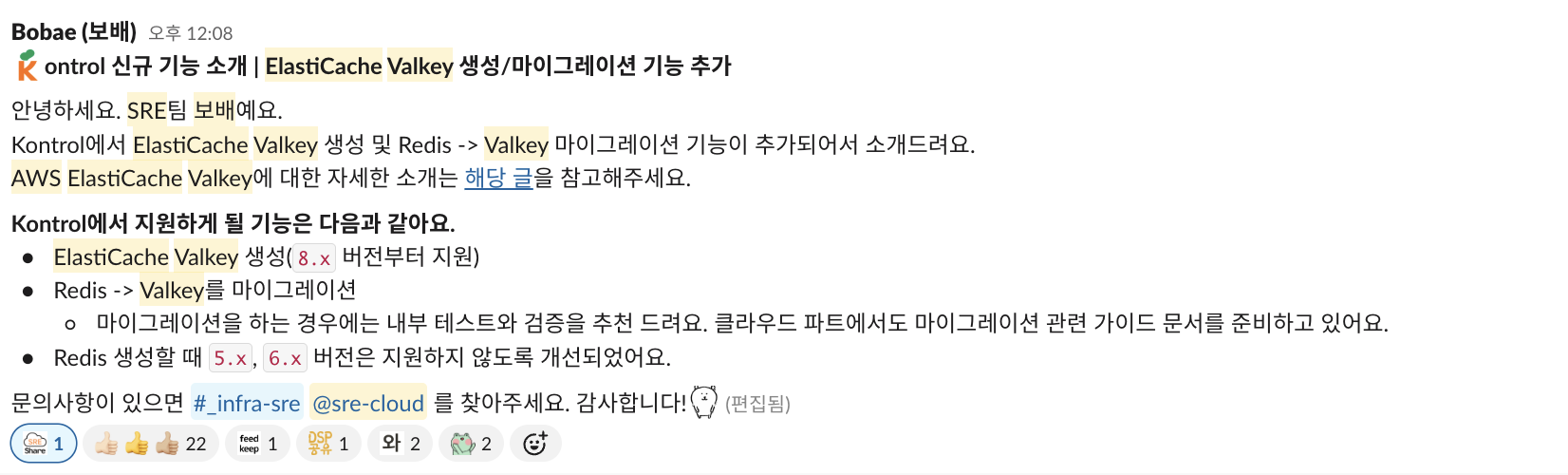
1) 서비스 캐시 성능 향상 및 인프라 비용 절감을 위한 ElastiCache for Valkey 도입
| Problem
- 안정적인 서비스 운영과 성능/비용 최적화를 위해 Valkey로의 전환을 추진
| Task
- 사내 플랫폼 ElastiCache 기능 개발 및 출시
- 사내 플랫폼 API 개발
- boto3 API 검토 및 기존 Redis 워크플로우 기반 Valkey 생성 기능 구현
- Engine Version 조회 API 리팩토링: Redis 5.x/6.x 지원 중단, Valkey 7.2/8.x 버전 추가
- Parameter Group 검증 로직 개선 (Redis ↔ Valkey 전환 시 engineType 버그 수정)
- 사내 플랫폼 UI 개발
- ElastiCache 생성 화면에 Redis/Valkey 엔진 선택
- 구버전(Redis 5.x, 6.x) 생성 제한 및 Valkey 버전 목록 확장
- 오픈 공지
- 사내 플랫폼 API 개발
- Valkey 모니터링을 위해 redis exporter v1.74.0 업그레이드
- 마이그레이션 검증 및 클라이언트 호환성 테스트
- Redis → Valkey 전환 시, 우려사항과 성능 비교에 대한 글 작성 후 전사 발표를 통한 공유
- 성능 비교 테스트: https://cobinding.tistory.com/309
- Redis → Valkey 전환 시, 우려사항과 성능 비교에 대한 글 작성 후 전사 발표를 통한 공유
- 프로젝트 완성도를 위한 외부 미팅 주도
- AWS ElastiCache Specialist와의 미팅을 통해 공식 가이드 및 베스트 프랙티스 검증
- 당근 내 ElastiCache를 적극적으로 사용하는 팀과의 미팅을 통해 실사용 사례 및 운영 노하우 공유(/w Lani)
- 관련 운영 지원
- 엔진 업데이트 주의사항 공유
- 사내 플랫폼 Redis 마이그레이션 작업
- Redis 관련 운영 질문 & 업데이트 고려사항 등





| Impact
- ElastiCache Redis → Valkey 마이그레이션을 통해 Alpha 21.9%, Prod 20.2%의 전환율 달성. Valkey는 Redis 대비 20% 저렴하여, 현재 전체 ElastiCache 비용의 약 4% 절감 효과.
- feature-platform 전환 사례: 대략 일 $500, 월 $15,000 절감
- Valkey 마이그레이션의 배경과 효과를 전사에 공유하고, 개발자 관점의 전환 가이드를 제공


2) 인프라 E2E 장애 모니터링 가시성 확보 1: CloudFront Additional Metrics
| Problem
- CloudFront는 모든 트래픽이 통과하는 첫 진입점이지만, 해당 구간의 모니터링 부재
| Task
- CloudFront 관련 모니터링 강화를 위한 Additional Metrics 활성화
- Additional Metrics 예상 비용 확인 후 적용

| Impact
- 지금까지 모니터링 되고있지 않은 영역들(Cache Hit, Origin Latency 등)에 대한 메트릭 확보 → 확보된 지표로 CloudFront 대시보드 제작 → CloudFront 모니터링 가시화
- 개발팀의 트래픽 확인 요청 해소

3) 인프라 E2E 장애 모니터링 가시성 확보 2: CloudFront Alert 시스템 구축
| Problem
- CloudFront 레거시 자원 점검을 계기로 인프라 최앞단인 CloudFront 모니터링을 강화
- Anomaly Request와 403 Error Rate 얼럿을 통해 트래픽 이상 감지 체계를 구축.
- 이후 false positive를 지속적으로 개선하며, 인프라 전반의 장애 대응 역량 강화를 목표로 진행중
| Task
- Datadog False Alert 평가 및 정리
- CF additional metrics 활성화 후 false alert 급증 → 레거시 자원 목록 추출 및 정리
- DDog Alert 제거 논의


- (위 결과에 따른) Grafana Alert Rule 설계 및 구현
- Request Anomaly
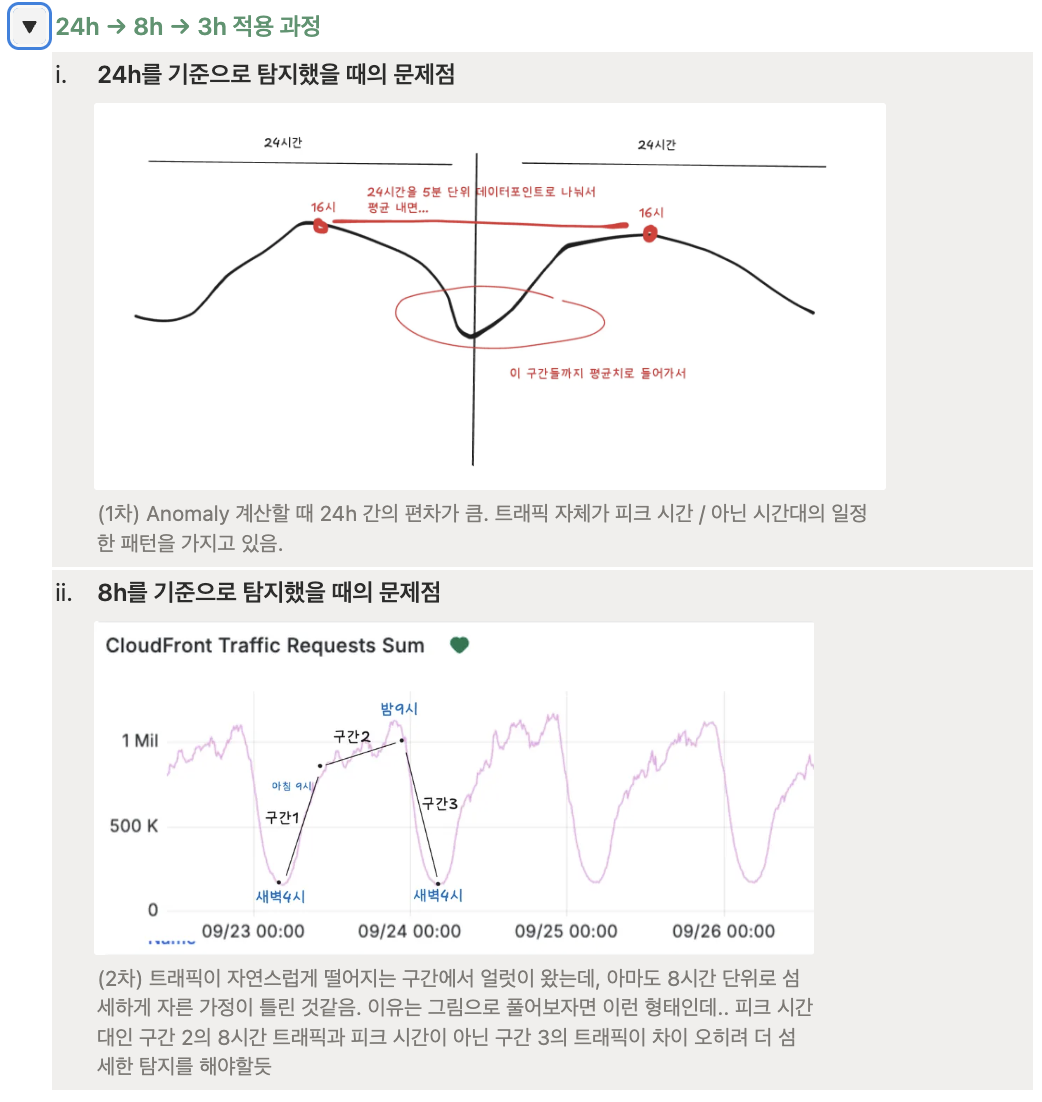
- Z-Score 기반 단기(3h)/장기(2주) 추세 반영 쿼리 직접 구현
- 테스트 결과를 분석하며 단기 추세 계산을 24h → 8h → 3h로 최종 적용
- 3h가 이상치 얼럿에 대한 최선의 판단이라고 결론
- 장기 & 단기 추세 알고리즘 문서 (링크 첨부)
- 트래픽 이상치 유효성 검증 결과 분석 문서 (링크 첨부)
- Alert 계산 효율을 위해 특정 규모의 트래픽이 있는 Dist에 대해서만 수행하도록 하한선 설정
- 하한선 측정 방법에 대한 문서: 위 알고리즘 문서와 동일
- Request Anomaly


- 403 Error Rate
- DDoS, Origin 권한 문제 감지
- 지속적인 False Positive 개선 (/w Hun, Aidan)
- false positive 최소화를 위한 개선 작업
- Alert 가독성을 위한 메시지 포맷 개선 (project_name, Distribution ID 등 정보 추가)
- 특정 프로젝트 자원 예외처리 및 사이드이펙트 대응
- Alert Delivery 적용하여 서비스팀 전달 체계 구축
- HAProxy, big-picture 등 Edge Case 예외처리
| Impact
- DDoS 감지
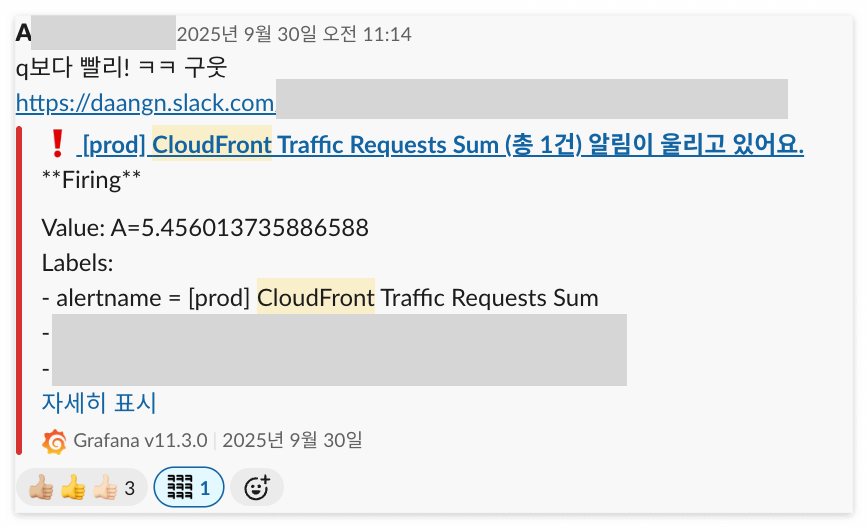
- 프로모션 이벤트 감지
- 프로모션 이벤트가 생기면 사용자가 몰리는데, 이에 대한 이상치도 감지되고 있다.
- 전사 Traffic Anomaly Detection 활용 기대
- 지속적인 False Positive 개선을 통해 인프라 앞단(CloudFront)의 트래픽 이상 감지 체계 고도화
- 향후 다른 레이어(istio 등)의 Anomaly Detection에도 해당 알고리즘 적용을 통한 모니터링 기대
4) 멀티 리전 환경에서 EC2 SSM 접근 로깅·암호화 구조 표준화
| Problem
- 리전별로 EC2 접근 로깅 및 암호화 설정이 서로 달라서, 리전마다 보안 설정을 확인해야 하는 비용이 발생할 수 있는 구조
- 주요 인스턴스 서버에 대한 접근 이력이 일관된 기준으로 관리되고 있지 않음
| Task
- 문제 발견 및 작업 직접 제안
- EC2 기능 사내 플랫폼 오픈 준비 중 SSM KMS 설정과 세션 로그 S3 버킷이 KR 리전에만 존재하는 것 발견
- 모든 환경/리전별 SSM 로킹 & 암호화 설정 표준화 필요성 직접 제안

- 글로벌 리전 SSM 인프라 구축
- Alpha/Prod 환경의 글로벌 리전에 세션 로그 S3 버킷 생성
- 리전별 KMS Key 생성
- SSM Session에 대해 KMS 암호화 설정 적용
| Impact
- SSM 접근 로깅과 암호화 설정을 적용 → 환경/리전 관계 없이 접근 기록과 암호화 적용 여부가 보장되도록 인프라 구조 표준화
- 세션 로그는 개인정보·인증 정보가 포함된 보안 핵심 로그이기에, 보안팀 일부 인원만 접근 가능하도록 설정
- 해당 작업을 통해 인프라 보안, SSM Logging 역량 강화
5) 전사 EC2 SSM 접근 관리를 위한 공용 IAM Policy 적용 및 인프라 표준화
| Problem
- SSM 로깅·암호화 설정 후
- CA 리전 인스턴스(i-056...)에서 SSM 접속 불가 문제
- EKS 클러스터 노드 접근 불가 문제
- 프로덕션 worker Role 권한 문제
| Task
- 미적용 Role 추출 및 문서화
- 환경/리전별로 SSM 접근 Policy 미할당 Role 추출

- 공용 Policy 정의 및 일괄 적용
-
- 공통 Policy 에 최소 권한 원칙 적용 (KMS, S3 PutObject 등)
- Alpha/Prod 환경의 모든 리전 Instance 관련 Role에 스크립트로 일괄 적용
- 공통 Policy 에 최소 권한 원칙 적용 (KMS, S3 PutObject 등)
-
- 적용 검증
- 환경/리전별 haproxy 머신에 SSM 명령어로 접근 가능 여부 검증
| Impact
- 전사 인프라 모든 EC2 인스턴스에 일관된 SSM 접근 정책 적용 완료
- 신규 인스턴스 생성 시에도 동일한 Policy가 자동 적용되는 표준화된 구조 확보
- 인프라실 위클리 발표를 통해 네트워크팀, DB팀 등 SSM 사용 부서에 변경사항 공유
6) 플랫폼 기반 인프라 프로비저닝·운영 자동화: EC2 Instance 기능 도입
| Problem
- (SRE) 인스턴스 타입, 스토리지, AMI, 보안 그룹, IAM Role 설정과 SSM 접근 방법을 매번 수동으로 처리
- 서버 스펙을 위한 커뮤니케이션 비용 증가
- 수동으로 설정하다보니 인프라 비표준화, 보안 유의사항을 누락하기 쉬운 구조
- (개발팀) 테스트용 서버가 필요할 때마다 SRE 요청 후 대기해야 하므로 PoC 속도 저하 및 자율성 제한
| Task
- Tech Spec

- EC2 Instance 서버 보안 강화를 위한 설정들 (w/보안팀)
- 모든 Instance에user-data Script를 통한 CrowdStrike 강제화
- 모든 Instance에 IMDSv2 설정 강제화
- Security Group Inbound 제한
- 보안상 최소 권한 부여를 위한 논의 스레드:
- 사내 플랫폼 EC2 생성·수정·삭제 작업

| Impact
- Test용 서버를 플랫폼으로 쉽고 빠르게 생성
- 앞으로 생성되는 EC2 Instance는 CrowdStrike, IMDSv2, SSM 접근 등 보안 사항 준수 → 인프라 표준화
7) CloudFront SaaS Manager 도입
| Problem
- FE 배포된 프론트엔드 사이트의 도메인 변경 건이 필요할 때마다 개발팀 → SRE 요청
- SRE는 사내 플랫폼 API를 통해 도메인/ACM 인증서를 직접 수정하고, 사내 플랫폼 DB 값도 별도로 수정해야 함
- 전사의 프론트엔드 배포 건수가 많아지면서 CloudFront, 서브도메인 관리 부담도 함께 증가
| Task
- 사내 플랫폼 API 구현 및 PoC 진행
- boto3 API로 multi-tenant 생성 기능 검증 및 테스트
- 개발팀 미팅 및 요구사항 협의
- 1차 (7/14): SaaS Manager 기능 소개 도입 가능성 논의
- 2차 (10/23): API 스펙 및 multi-tenant 구조 논의
- 결정 사항: FE 배포 전용 multi-tenant 1개 구성, 사내 플랫폼 즉시 도입은 보류 SRE팀 내부 검토 및 결정
- 구조 설계 재검토 및 선행 작업
- 초기 구조 설계가 복잡해 동료와 협업하여 워크플로우 재검토
- SaaS Manager 도입을 위한 선행 작업으로 사내 플랫폼 도메인 스코프 정리 진행
- 도메인 스코프 정리 완료 후 CF multi-tenant 사내 플랫폼 API 스펙 재정의
| Impact
- 사내 플랫폼 StaticWebsite 도메인 스코프 정리 및 개선 완료
- PoC 기술 검토 완료, FE 배포 전체 방향성 논의로 확장
8) AWS 비용 이상치 탐지 시스템 구축을 통한 비용 관리
| Problem
- MAU 2000만, 서비스가 점점 커지고 다양한 시도를 하면서 인프라 비용 꾸준히 증가
- GCP는 비용 이상치 감지 시스템이 구축되어있지만, AWS는 수동 확인에 의존
- 이상 비용은 운영 이슈로 이어질 수 있고, 인프라 비용 관리 관점에서 중요도가 높음.
| Task
- 출시 공지(기능, 사용법, 실제 탐지 내용)

- 프로젝트 단계
- 중간 과정 및 의사결정에 대한 정리 문서 (문서 링크)
- Slack 채널 자동 알림
| Impact
- 결과물: threshold=$1,000이 넘는 비용 이상치에 대한 모니터링
- 모니터링 과정을 거쳐 threshold 값 설정
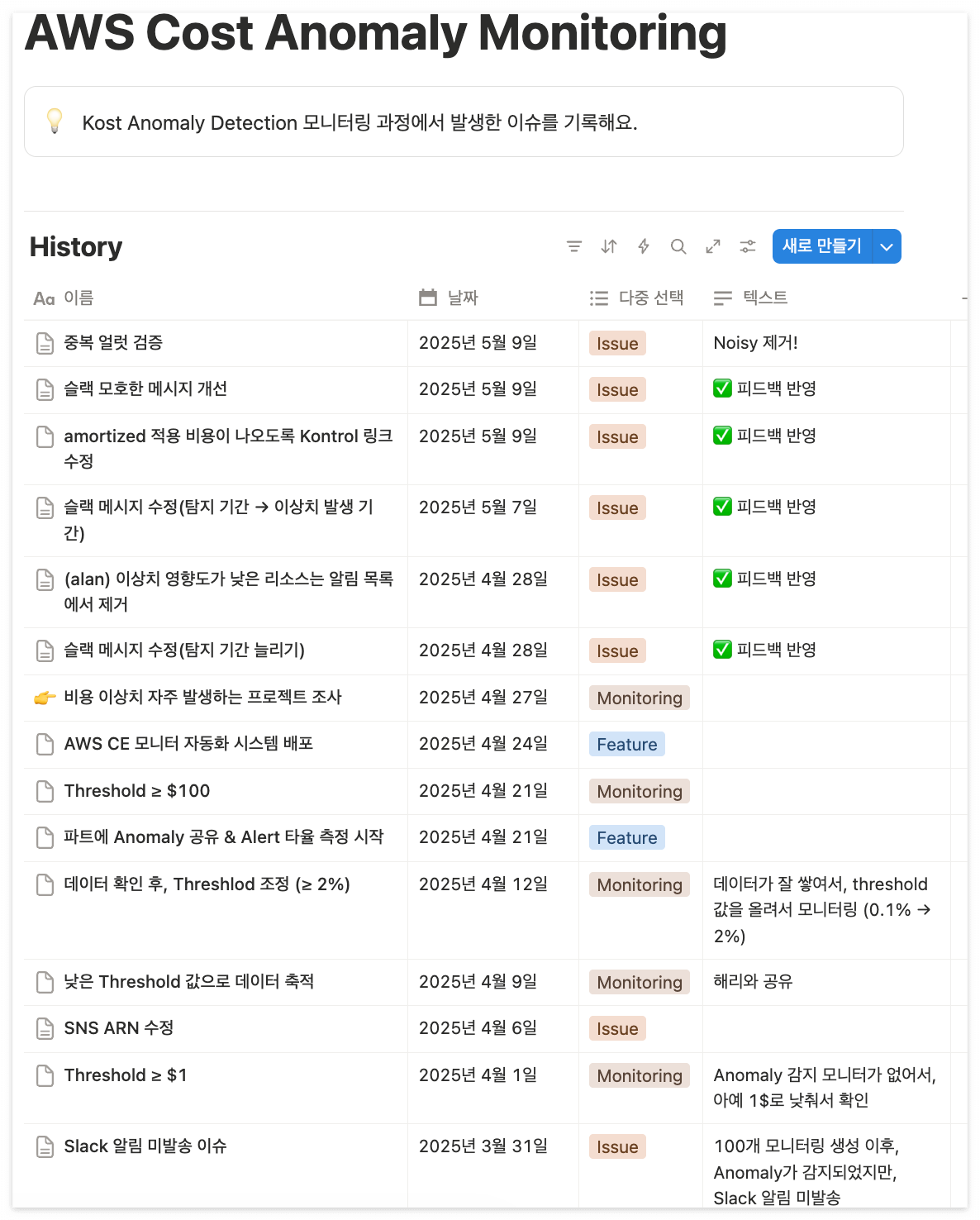
- 예시 얼럿 유형:
- 예시1(MSK 스케일업)
- 예시2(prod---x 관련 DB 스케일업)
- 예시3(ppxx-platform $2,000 증가)
- 얼럿 유효성이 검증되어 개발팀 온콜 멘션 그룹 활성화 계획(2026 1분기)
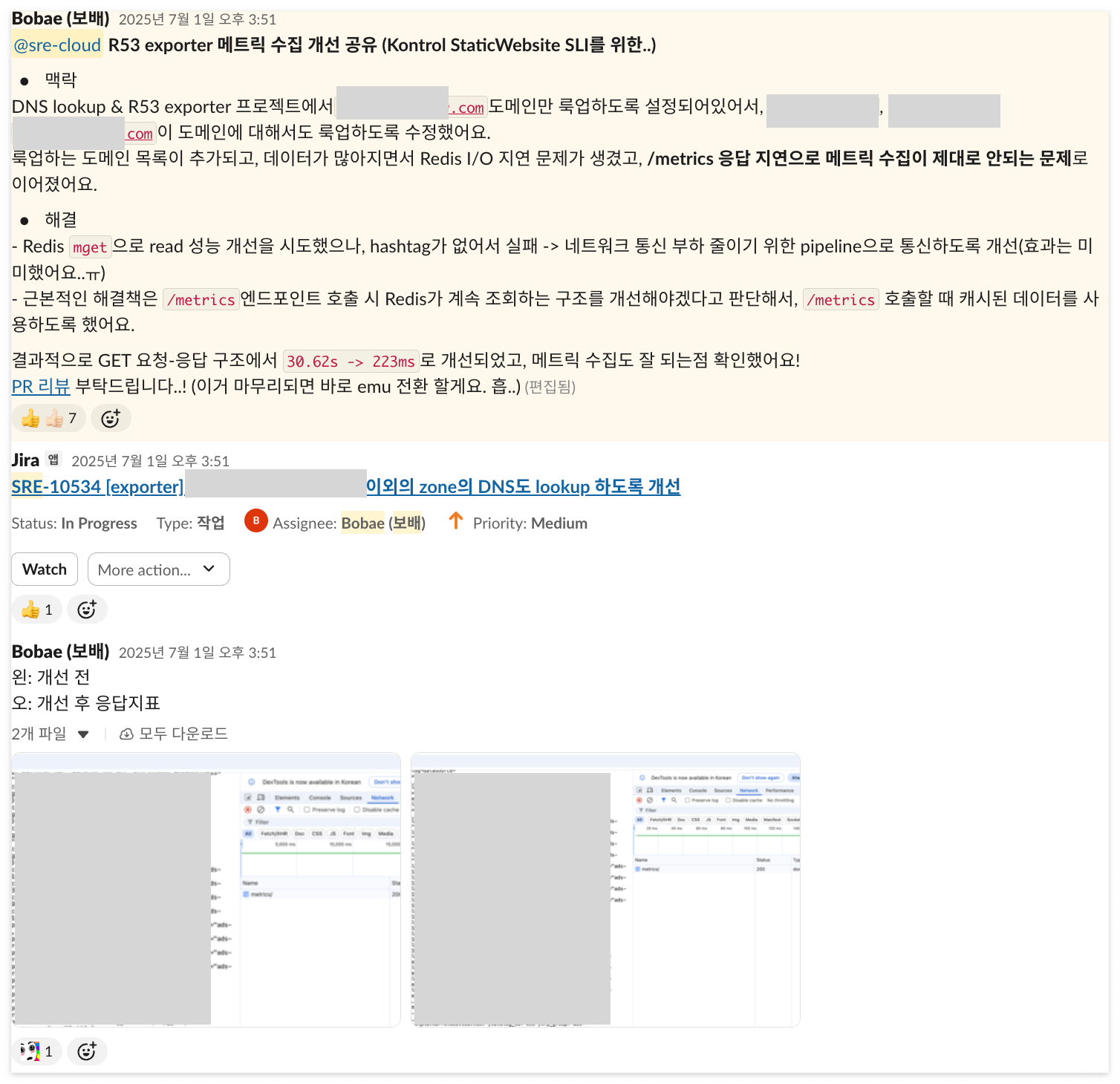
9) StaticWebsite SLI 정의 및 사내 플랫폼 대시보드 구성
| Problem
- StaticWebiste(R53, CloudFront, S3) 장애 감지 및 대응 체계 강화
- 현황: CloudFront 관련 장애 발생 시 에러 조기 감지율 부족
- 목표: 에러 캐치율 개선을 통한 장애 대응 시간 단축
| Task
- CloudFront SLI 정의를 위한 아이데이션
- CloudFront SLI Info, success_request 관련 작업
- CloudFront 메트릭을 위한 레거시 Tag 제거 작업
- R53 SLI 개선 작업
- 사내 플랫폼 SLI 가시화 작업
- 클라우드파트 SLI 문서 정리 작업
| Impact
- 사내 플랫폼 StaticWebsite 모니터링 가시화
- R53 Exporter DNS Lookup 대상 추가
- R53 Exporter 메트릭 수집 성능 개선
운영 업무
| 장애 대응
| Pay Oncall
- SRE 클라우드 파트 Pay 업무 온콜 담당
- 목적: 온콜 운영 경험을 통한 Pay 업무 이해도 향상 및 파트 내 지식 공유
- Pay 업무 사흘 간 느낀 점 회고
- 온콜 일지
- 목적: 온콜 운영 경험을 통한 Pay 업무 이해도 향상 및 파트 내 지식 공유
| Market Oncall
| 기타 운영
- 멀티 리전 Prod 환경의 KMS 삭제 및 비활성화 권한 Deny (/w Lu)
- AWS GuardDuty 비용 증가 원인 파악을 위해 비용 모니터링 Budgets 설정
- StaticWebsite 관련 도메인 변경
발표 및 공유
[25.03.07 | 인프라 위클리] 신규입사자가 느낀 개선점과 방향성 발표
[25.05.16 | 인프라 위클리] Kost Anomaly Detection 기능 소개
[25.07.18 | 인프라 위클리] CloudFront Saas Manager 기능 소개 및 협업 과정
[25.08.28 | Tech Allhands] Kontrol ElastiCache for Valkey 출시와 관련 내용
[25.12.05 | 인프라 위클리] Kontrol EC2 도입 과정 중 인프라 & 보안 개선점 소개
기타
[25.09.03] Builder's Camp 해커톤 시뮬레이션 참여
'회고 & 후기 > 회고 & 후기' 카테고리의 다른 글
| [회고] 사내 해커톤 시뮬레이션 회고! (0) | 2025.09.24 |
|---|---|
| [Archive] 2024 정보처리기사 필기 합격 후기 (0) | 2024.02.22 |
| [인턴십] 2023 ICT 학점연계 인턴십 회고 (8) | 2023.12.24 |
| [공모전] 2023 IT 창업 개발 동아리 멋쟁이 사자처럼 11기 해커톤 후기 (2) | 2023.08.24 |
| [공모전] 2021 슬기로운 코딩생활 최우수상 후기 (1) | 2023.08.02 |